DALL-E (Zero-Shot Text-to-Image Generation) -PART(2/2)Link to my deep learning blogs : https://rakshithv-deeplearning.blogspot.com/Apr 30, 2022Apr 30, 2022
DALL-E (Zero-Shot Text-to-Image Generation) -PART(1/2)Link to my deep learning blogs : https://rakshithv-deeplearning.blogspot.com/Apr 15, 2022Apr 15, 2022
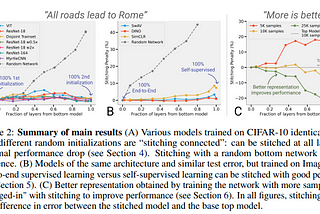
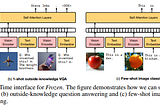
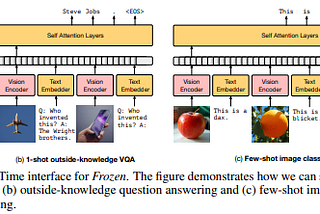
NeurIPS 2021 — Curated papers — Part 2Link to my deep learning blogs : https://rakshithv-deeplearning.blogspot.com/Dec 28, 2021Dec 28, 2021
NeurIPS 2021 — Curated papers — Part 1UniDoc: Unified Pretraining Framework for Document UnderstandingDec 18, 2021Dec 18, 2021
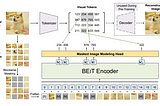
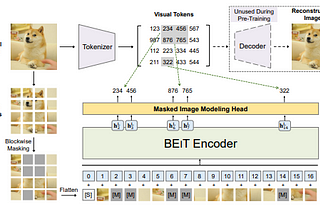
BEIT: BERT Pre-Training of Image TransformersLink to my blogging profile : https://rakshithv-deeplearning.blogspot.com/Sep 12, 2021Sep 12, 2021
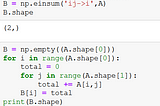
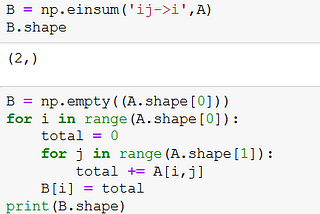
Einsum equation:Link to my blogging profile : https://rakshithv-deeplearning.blogspot.com/Jun 11, 2021Jun 11, 2021
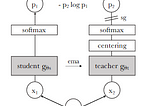
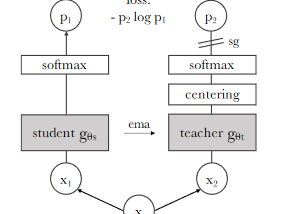
Emerging Properties in Self-Supervised Vision Transformers (DINO)Link to my blogging profile : https://rakshithv-deeplearning.blogspot.com/May 23, 2021May 23, 2021
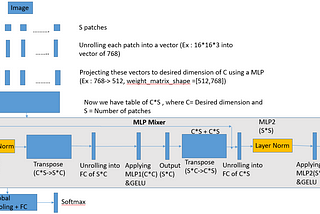
MLP-Mixer: An all-MLP Architecture for VisionLink to my blogging profile : https://rakshithv-deeplearning.blogspot.com/May 23, 2021May 23, 2021
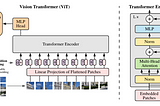
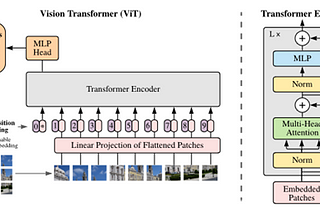
An Image is Worth 16x16 Words: Transformers for Image Recognition at ScaleLink to my blogging profile : https://rakshithv-deeplearning.blogspot.com/May 23, 2021May 23, 2021